
1. 基本概念
n-gram
- 当 n=1 时,即出现在第 i 位上的基元 $w_i$ 独立于历史。一元文法也被写为uni-gram 或 monogram;
- 当 n=2 时, 2-gram (bi-gram) 被称为1阶马尔可夫链;
- 当 n=3 时, 3-gram(tri-gram)被称为2阶马尔可夫链,依次类推。
$w_i$ 可以是字、词、短语或词类等等,称为统计基元。通常以“词”代之
为了保证条件概率在 i=1 时有意义,同时为了保证句子内所有字符串的概率和为 1,
。。。
如果汉字的总数为:N
一元语法: 1)样本空间为 N
2)只选择使用频率最高的汉字
2元语法: 1)样本空间为 $N^2$
2)效果比一元语法明显提高
估计对汉字而言四元语法效果会好一些
2. 参数估计
$p(w_i|w^{i-1}{i-n+1})=\frac{c(w^{i-1}{i-n+1})}{\sum_{w_i}c(w^{i-1}_{i-n+1})}$
分母:历史串出现次数;分子:同时出现次数
3. 数据平滑
测试样本的语言模型困惑度越小越好
交叉熵:
$H_p(T)=-\frac{1}{W_T}\log p(T)$
$W_T$ 是测试文本T 的词数,$p(T)=\prod\limits_{i=1}^{l_T}p(t_i)$,测试语料 T 由 $l_T$个句子构成
加一平滑
2-gram 分母加|V|,V 为被考虑语料的词汇量(全部可能的基元数)
减值法/折扣法
修改训练样本中事件的实际计数,使样本中(实际出现的)不同事件的概率之和小于1,剩余的概率量分配给未见概率。
Good-Turing 估计
Back-off (后备/后退)方法/Katz 后退法
当某一事件在样本中出现的频率大于阈值K (通常取 K 为0 或1)时,运用最大似然估计的减值法来估计其概率,否则,使用低阶的,即 (n-1)gram 的概率替代n-gram 概率,而这种替代需受归一化因子$\alpha$的作用。
绝对减值法
线性减值法
- Good-Turing 法:对非0事件按公式削减出现的次数,节留出来的概率均分给0概率事件。
- Katz 后退法:对非0事件按Good-Turing法计算减值,节留出来的概率按低阶分布分给0概率事件。
- 绝对减值法:对非0事件无条件削减某一固定的出现次数值,节留出来的概率均分给0概率事件。
- 线性减值法:对非0事件根据出现次数按比例削减次数值,节留出来的概率均分给0概率事件。
删除插值法
用低阶语法估计高阶语法,即当3-gram的值不能从训练数据中准确估计时,用 2-gram 来替代,同样,当2-gram 的值不能从训练语料中准确估计时,可以用1-gram 的值来代替
4. 语言模型的自适应
问题:
- 语料来自不同的领域,有差异性,敏感。
- 独立性假设(只和前n-1个词相关)在实际中不成立
基于缓存的语言模型 Cache-based
在文本中刚刚出现过的一些词在后边的句子中再次出现的可能性往往较大,比标准的 n-gram 模型预测的概率要大。针对这种现象,cache-based自适应方法的基本思路是:语言模型通过n-gram 的线性插值求得
基于混合方法的语言模型 Hybrid
由于大规模训练语料本身是异源的(heterogenous),而测试语料一般是同源的(homogeneous),因此,为了获得最佳性能,语言模型必须适应各种不同类型的语料对其性能的影响。
将语言模型划分成 n 个子模型 $M_1, M_2, …, M_n$,整个语言模型的概率通过线性插值公式计算得到
基于最大熵的语言模型 ME-based
通过结合不同信息源的信息构建一个语言模型。每个信息源提供一组关于模型参数的约束条件,在所有满足约束的模型中,选择熵最大的模型。
考虑两个语言模型 $M_1$ 和 $M_2$,假设 $M_1$是标准的 2 元模型,表示为 f 函数,$M_2$ 是距离为2的2元模型 (distance-2 bigram),定义为g函数。用线性插值方法通过取这两个概率估计的平均值,并采用后备(backing-off) 平滑技术来解决这个问题
5. 语言模型应用举例
分词问题

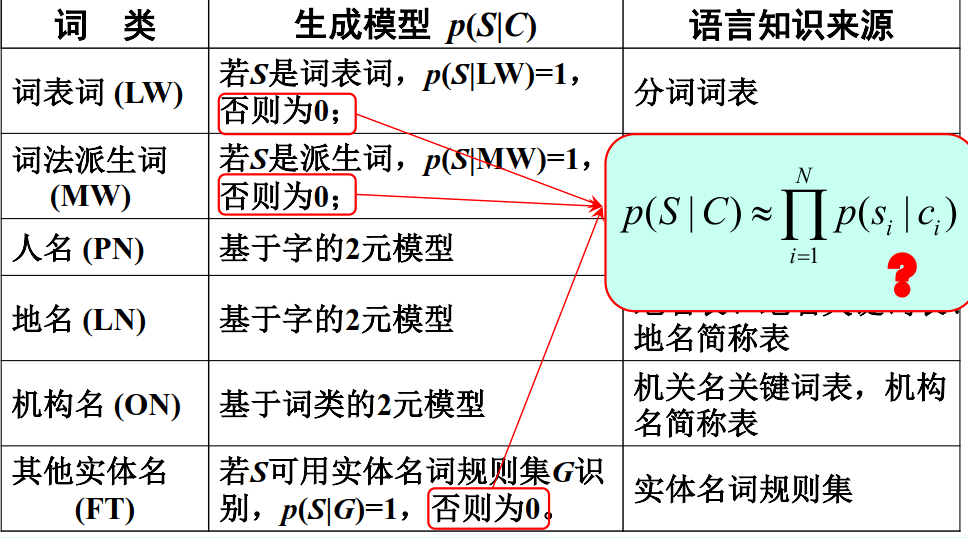
分词与词性标注一体化方法
句子S,单词串$W=w_1w_2\dots w_n$,词性标注串$T=t_1t_2\dots w_n$
基于词性的三元统计模型
$P(W,T)=p(W|T)P(T)\approx \prod\limits_{i=1}^np(w_i|t_i)p(t_i|t_{i-1}t_{i-2})$
基于单词的三元统计模型
$P(W,T)=p(T|W)P(W)\approx \prod\limits_{i=1}^np(t_i|w_i)p(w_i|w_{i-1}w_{i-2})$
分词与词性标注一体化模型
$P(W,T)=\alpha \prod\limits_{i=1}^np(w_i|t_i)p(t_i|t_{i-1}t_{i-2})+ \beta \prod\limits_{i=1}^np(t_i|w_i)p(w_i|w_{i-1}w_{i-2})$
$p(t_i | w_i)$ 对分词无帮助,且在分词确定后对词性标注又会增添偏差。因此,在实现这一模型时,可以仅取公式中的语言模型部分,而舍弃词性标注部分,并令$\alpha=1$,仅保留加权系统 $\beta$
$\beta$=词典中词w的个数 / 词性t 的种类数