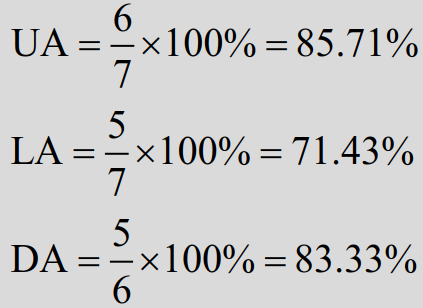1. 概述
类型:
- 短语结构分析(Phrase parsing)
- 完全句法分析(Full parsing)
- 局部句法分析(Partial parsing)
- 依存句法分析(Dependency parsing)
2. 短语结构分析
英语中的结构歧义随介词短语组合个数的增加而不断加深的,这个组合个数我们称之为开塔兰数,$C_N=\Bigg( \begin{aligned}2n \ n\end{aligned}\Bigg)\frac{1}{n+1}=\frac{(2n)!}{(n!)^2(n+1)}$
基本方法和开源的句法分析器:
基于CFG规则的分析方法:
线图分析法(chart parsing)
CYK 算法
Earley (厄尔利)算法
LR 算法 / Tomita 算法 … …- Top-down: Depth-first/ Breadth-first
- Bottom-up
基于 PCFG 的分析方法 PCFG: Probabilistic Context-Free Grammar
3. 线图分析法







Chart算法的时间复杂度为:
$O(Kn^3)$ (K 为一常数, n是句子长度)
4. CYK分析算法








5. 概率上下文无关文法(PCFG)


6. 依存句法分析
在依存语法理论中,“依存”就是指词与词之间支配与被支配的关系,这种关系不是对等的,而是有方向的。
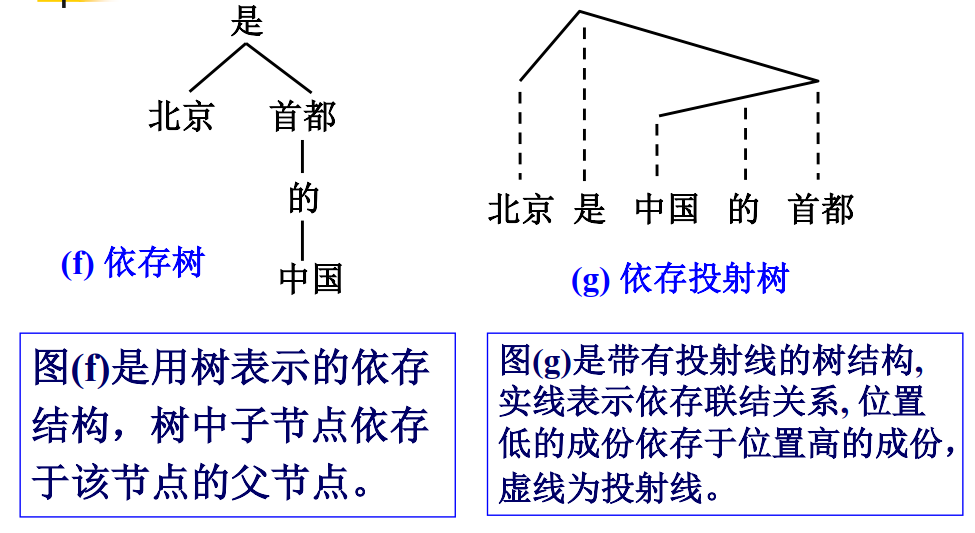
对依存图和依存树的形式约束为:
- 单一父结点(single headed)
- 连通(connective)
- 无环(acyclic)
- 可投射(projective)
由此来保证句子的依存分析结果是一棵有“根(root) ”的树结构。
建立一个依存句法分析器一般需要完成以下三部分工作:
- 依存句法结构描述
- 分析算法设计与实现
- 文法规则或参数学习
目前依存句法结构描述一般采用有向图方法或依存树方法,所采用的句法分析算法可大致归为以下4类:
- 生成式的分析方法(generative parsing)
- 判别式的分析方法(discriminative parsing)
- 决策式的(确定性的)分析方法(deterministic parsing)
- 基于约束满足的分析方法(constraint satisfaction parsing)
7. 依存句法分析器性能评价
无标记依存正确率(unlabeled attachment score, UA):
所有词中找到其正确支配词的词所占的百分比,没有找到支配词的词(即根结点)也算在内。
带标记依存正确率(labeled attachment score, LA):
所有词中找到其正确支配词并且依存关系类型也标注正确的词所占的百分比,根结点也算在内。
依存正确率(dependency accuracy, DA):
所有非根结点词中找到其正确支配词的词所占的百分比。
根正确率(root accuracy, RA):有两种定义方式:
正确根结点的个数与句子个数的比值;
另一种是所有句子中找到正确根结点的句子所占的百分比。
对单根结点语言或句子来说,二者是等价的。
- 完全匹配率(complete match, CM):所有句子中无标记依存结构完全正确的句子所占的百分比。