
1. 基本翻译方法
- 直接转换法
- 基于规则的翻译方法
- 基于中间语言的翻译方法
- 基于语料库的翻译方法
- 基于事例的翻译方法
- 统计翻译方法
- 神经网络机器翻译
直接转换法
从源语言句子的表层出发,将单词、短语或句子直接置换成目标语言译文,必要时进行简单的词序调整。对原文句子的分析仅满足于特定译文生成的需要。
基于规则的翻译方法(Rule-based)
(a) 对源语言句子进行词法分析
(b) 对源语言句子进行句法/语义分析
(c) 源语言句子结构到译文结构的转换
(d) 译文句法结构生成
(e) 源语言词汇到译文词汇的转换
(f ) 译文词法选择与生成
基于中间语言的翻译方法(Interlingua-based)
输入语句->中间语言->翻译结果
2. 统计机器翻译
噪声信道模型
一种语言T 由于经过一个噪声信道而发生变形,从而在信道的另一端呈现为另一种语言 S (信道意义上的输出,翻译意义上的源语言)。翻译问题实际上就是如何根据观察到的 S,恢复最为可能的T 问题。
统计翻译中的三个关键问题:
估计语言模型概率 p(T);
n-gram
估计翻译概率 p(S|T);
对位模型(alignment model)
源语言句子 $S=s_1s_2\dots s_m$有m个单词 ;目标语言句子$T=t_1t_2\dots t_l$有l个单词
对位模型 A 视为隐含变量,则:$P(S|T)=\sum_AP(S,A|T)$,每一种对位序列表示成:$A=a_1a_2\dots a_m$

快速有效地搜索T 使得 p(T)×p(S | T) 最大。
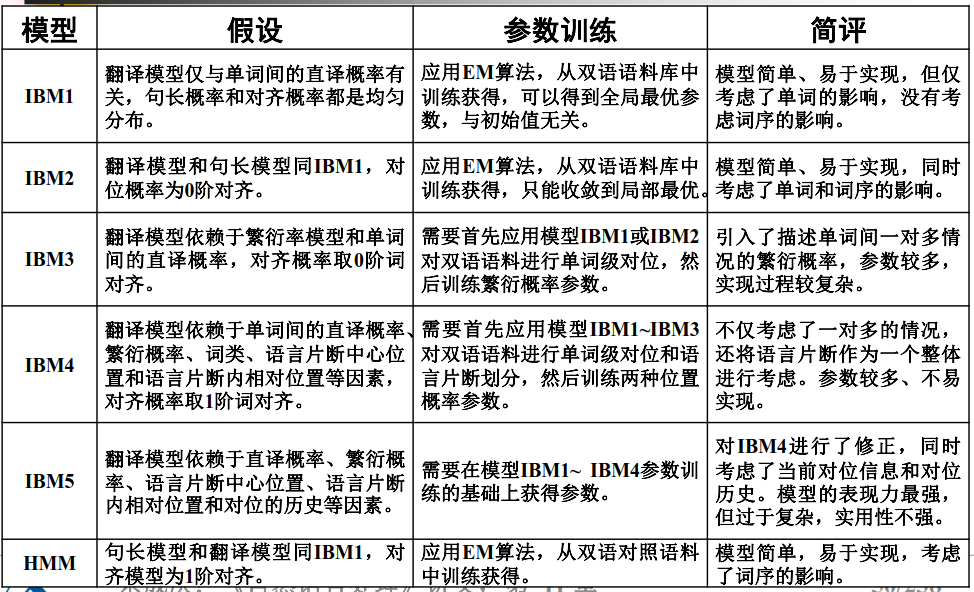
IBM 翻译模型1





根据IBM翻译模型1,由英语句子e 生成法语句子f 的实现过程:
(1) 根据概率分布为法语句子f 选择一个长度m;
(2) 对于每一个j = 1, 2, …, m,根据均匀分布原则从 0, 1, …, l 中选择一个值给$a_j$;
(3) 对于每一个 j = 1, 2, …, m,根据概率$𝒑 (𝒇𝒋|𝒆{𝒂_𝒋})$ 选择一个法语单词$f_j$。

IBM 翻译模型2
在IBM 模型2中,除了假定概率 依赖于位置 j、对位关系$a_j$ 和源语言句子长度m以及目标语言句子长度l 以外,另外两个假设与IBM模型1中的假设一样。
引入了对位概率(alignment probabilities)的概念:
$a(a_j|j,m,l)=P(a_j|a_i^{j-1},s_1^{j-1},m,l)$
对于每一个三元组(j, m, l),对位概率满足如下约束条件:
$\sum_{i=0}^la(i|j,m,l)=1$

根据 IBM模型2,由英语句子e 生成法语句子f 的实现过程:
(1)根据概率分布为法语句子f 选择一个长度m;
(2)对于每一个 j = 1, 2, …, m,根据概率分布 $a(a_j | j, l, m)$从0, 1, …, l中选择一个值给$a_j$;
(3)对于每一个 j = 1, 2, …, m,根据概率选择一个法语单词$f_j$。

IBM 翻译模型3
定义:在随机选择对位关系的情况下,与目标语言句子中的单词 t 对应的源语言句子中的单词数目是一个随机变量,不妨记做$\phi_t$,我们称该变量为单词t 的繁衍能力或产出率(fertility)。一个具体的取值记做:$\phi_t$实际上,所谓的繁衍能力就是目标语言单词与源语言单词之间一对多的关系。
定义:假设给定一个目标语言句子T,T中的每一个单词t 在源语言句子中可能有若干个词与之对应,源语言句子中所有与t 对位的单词列表我们称之为t的一个片断(tablet)**,这个片断可能为空。一个目标语言句子T 的所有片断的集合是一个随机变量,我们称之为T的片断集(tableau),记做符号R。T 的第i 个单词的片段也是一个随机变量**,不妨记做$R_i$,那么,T 的第i个单词的片断中第k个源语言单词也是一个随机变量,记做$R_{ik}$。


根据 IBM模型3, 一个英语句子e 翻译成法语句子f 的工作过程如下:
(1) 对于英语句子中的每一个单词e,选择一个产出率$\phi$,其概率为 $n(\phi|e)$;
(2) 对于所有单词的产出率求和,得到 m-prime;
(3) 按照下面的方式构造一个新的英语单词串:删除产出率为0的单词,复制产出率为1的单词,复制两遍产出率为2的单词,依此类推;
(4) 在这m-prime个单词的每一个后面,决定是否插入一个空单词NULL,插入的概率为$p_1$,不插入的概率为$p_0$;
(5) 设$\phi_0$为插入空单词 NULL 的个数;
(6) 设m为目前总单词的个数:$m-prime +\phi_0$;
(7) 根据概率表 p(f|e) 将每一个单词e替换为法语单词f ;
(8) 对不是由空单词 NULL 产生的每一个法语单词,根据概率表 d(j |i, l, m) 赋予一个位置。这里j 是法语单词在法语句子中的位置,i是产生当前这个法语单词的英语单词在其句子中的位置,l是英语句子的长度,m 是法语句子的长度;
(9) 如果任何一个法语句子的位置被多重登录(含一个以上的单词),则失败返回;
(10) 给空单词NULL产生的法语单词在句子中赋予一个位置,这些位置必须是没有被占领的空位置。任何一个赋值都被认为是等概率的,概率值为$1/\phi_0$;
(11) 读出法语单词串,其概率为上述每一步概率的乘积,按概率大小输出结果。
模型 4: 考虑片断的中心词的概率和其他单词的位置概率。
模型 5: 源语言句子单词间的相对位置。
3. 基于短语的翻译模型
基于最大熵的方法 (判别式)
任务:
对于一个随机事件,假设已经有了一组样例,我们希望建立一个统计模型来模拟这个随机事件的分布
目标:
对于一组特征,使得统计模型在这一组特征上的模型分布与样例中的经验分布完全一致,同时不对未知事件作任何假设,即保证这个模型尽可能的“均匀”(也就是要求模型的熵值达到最大)


翻译基本单元由词转向短语
基于词的翻译模型的问题:
很难处理词义消岐问题
很难处理一对多、多对一和多对多的翻译问题在基于短语的模型中,直接将繁衍率信息、上下文信息以及局部对位调序信息记录在翻译规则中。

短语划分模型
目标:将一个词序列如何划分为短语序列
方法:一般假设每一种短语划分方式都是等概率的

短语调序模型:
两种常用方法:
- 距离跳转模型
- 分类模型

4. 基于短语的翻译模型的解码算法

5. 基于短语模型的SMT系统实现

6. 基于层次化短语的翻译模型
基于层次化短语的翻译模型首先利用层次化短语产生句子的局部翻译,然后,像常规的基于短语的模型一样,将这些局部的翻译顺序地连接起来,从而形成整个句子的翻译。


7. 树翻译模型
树到串的翻译模型

树到树的翻译模型

串到树的翻译模型



8. 系统融合
系统融合方法:
- 句子级系统融合
- 短语级系统融合
- 词语级系统融合
9. 译文评估方法
常用的评测指标:
主观评测
客观评测
(1) 句子错误率:译文与参考答案不完全相同的句子为错误句子。错误句子占全部译文的比率。
(2) 单词错误率(Multiple Word Error Rate on Multiple Reference, 记作 mWER):分别计算译文与每个参考译文的编辑距离,以最短的为评分依据,进行归一化处理
(3)与位置无关的单词错误率 (Position independent mWER, 记作mPER ):不考虑单词在句子中的顺序
(4) METEOR 评测方法 对候选译文与参考译文进行词对齐,计算词汇完全匹配、词干匹配、同义词匹配等各种情况的准确率(P)、召回率(R)和F平均值
(5) BLEU评价方法 [Papineni, 2002] -BiLingual Evaluation Understudy, IBM
基本思想:
将机器翻译产生的候选译文与人翻译的多个参考译文相比较,越接近,候选译文的正确率越高。
实现方法:
统计同时出现在系统译文和参考译文中的n 元词的个数,最后把匹配到的n元词的数目除以系统译文的n元词数目,得到评测结果。







(6) NIST 评测方法 National Institute of Standards and Technology
基本思想:BLEU评分公式中采用的n元语法同现概率的几何平均方法使评分值对于各种n元语法同现的比例具有相同的敏感性,但实际上,这种做法存在着潜在的矛盾,因为n值较大的统计单元出现的概率较低。因此,NIST的研究人员提出了另外一种处理方法,就是用n-gram同现概率的算术平均值取代几何平均值。另外,如果一个n元词在参考译文中出现的次数越少,表明它所包含的信息量越大,那么,它对于该n元词就赋予更高的权重。
10. 神经机器翻译
神经网络语言模型
基于计数的N-元语言模型

问题①:数据稀疏 N-元组“很 无聊”未出现过,则回退
问题②:忽略语义相似性 “无聊”与“枯燥”虽语义相似,但无法共享信息
基于分布式表示的N-元语言模型