
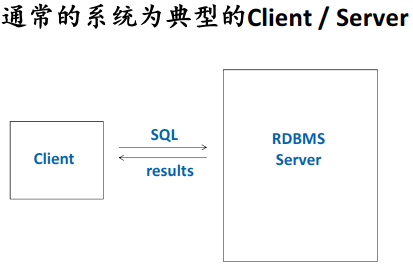
关系型数据库
数据库系统架构
Database Management System(数据库管理系统)
RDBMS: Relational Database Management System(关系型数据库系统)

SQL Parser
SQL 语句的程序->解析好的内部表达(例如:parsing tree)
语法解析,语法检查,表名、列名、类型检查
Query Optimizer
产生可行的query plan
估计query plan的运行时间和空间代价
在多个可行的query plans中选择**最佳的query plan**
Data storage and indexing
如何在硬盘上存储数据
如何高效地访问硬盘上的数据
Buffer pool
在内存中缓存硬盘的数据
提高性能,减少I/O
Execution Engine
根据query plan,完成相应的运算和操作
数据访问
关系型运算的实现
Transaction management:事务管理
目标是实现ACID
进行logging写日志,locking加锁
保证并行transactions事务的正确性
数据存储与访问
数据表
RDBMS最小的存储单位是database page size,Data page size 可以设置为1~多个文件系统的 page,例如,4KB, 8KB, 16KB, …


数据的顺序访问
顺序读取Student表的每个page
对于每个page,顺序访问每个tuple
索引
Selective Data Access (有选择性的访问)
使用index(索引)
Tree based index
有序,支持点查询和范围查询
Hash based index
无序,只支持点查询


每个节点是一个page
所有key存储在叶子节点
内部节点完全是索引作用

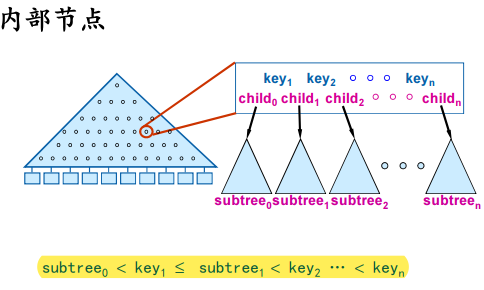
Search
从根节点到叶节点
每个节点中进行二分查找
内部节点:找到包括search key的子树
叶节点:找到匹配
Search代价
共有N个key
每个节点的child/pointer个数为B
总I/O次数=树高:$O(\log_BN)$
总比较次数
每个节点内部二分查找:$O(\log_2B)$
$O(\log_BN) x O(\log_2B) = O(\log_2N)$
Insertion
Search 然后在节点中插入
叶节点未满,插入叶节点
叶节点满了,node split(节点分裂)
Deletion
Search 然后在节点中删除
node merge?
原设计:当节点中key个数小于一半
实际实现:数据总趋势是增长的
可以只有节点为空时才node merge
或者完全不进行node merge
Range Scan
找到起始叶结点,包括范围起始值
沿着叶的链接读下一个叶结点
直至遇到范围终止值
Clustered index(主索引)与Secondary index(二级索引)
Clustered: 记录就存在index中,记录顺序就是index顺序
需要处理每一个记录顺序读每一个page
Secondary: 记录顺序不是index顺序,index中存储page ID和in-page tuple slot ID.
有选择地处理记录随机读相关的page
缓冲池Buffer Pool
提高性能,减少I/O
数据访问的局部性(locality)
Temporal locality (时间局部性)
同一个数据元素可能会在一段时间内多次被访问
Buffer pool
Spatial locality (空间局部性)
位置相近的数据元素可能会被一起访问
Page为单位读写
Buffer pool的内存空间分成page大小的单元(frame),每个frame可以缓冲硬盘中的一个page.
Replacement (替换)
如果这个page 被修改过,那么需要写回硬盘
Replacement Policies(替换策略)
Random:随机替换
FIFO(First In First Out):替换最老的页
LRU (Least Recently Used):最近最少使用
Clock算法

运算的实现
Operator tree
Query plan 最终将表现为一棵Operator Tree
每个节点代表一个运算
运算的输入来自孩子节点
运算的输出送往父亲节点
####Selection & Projection
Join
Nested loop
>Nested Loop Join 双循环
>
>Block Nested Loop Join 一次读入内存大小
>
>Index Nested Loop Join 建立中间索引Hashing
读R建立hash table; 读S访问hash table找到所有的匹配;
R比内存大怎么办?
把R和S划分成小块 PartitionID = hash(join key) % PartitionNumber
Rj中记录的匹配只存在于相应的Sj中
匹配的记录hash (join key)必然相同
GRACE Hash Join 线性时间
Sorting
如果把R按照R.a的顺序排序,把S按照S.b的顺序排序,那么可以Merge(归并)找出所有的匹配,当一个表已经有序的情况下,会被使用
事务处理
ACID
事务中的所有操作满足ACID性质
- Atomicity(原子性)要么完全执行,要么完全没有执行
- Consistency(一致性)从一个正确状态转换到另一个正确状态
- Isolation(隔离性)每个事务与其它并发事务互不影响
- Durability(持久性)Transaction commit后,结果持久有效,crash也不消失
Concurrency Control (并发控制)
Serializable(可串行化):并行执行结果=某个顺序的串行执行结果
- Read uncommitted data (读脏数据) (写读)在T2 commit之前,T1读了T2已经修改了的数据
- Unrepeatable reads(不可重复读) (读写)在T2 commit之前,T1写了T2已经读的数据
- Overwrite uncommitted data (更新丢失) (写写)在T2 commit之前,T1重写了T2已经修改了的数据
Pessimistic (悲观) 假设:数据竞争可能经常出现,保证数据竞争不会出现
Optimistic (乐观) 假设:数据竞争很少见,在提交前检查是否没有数据竞争
Pessimistic: 加锁